Website (Langzeit)Pflege [Updates]
![Website (Langzeit)Pflege [Updates]](https://images.unsplash.com/photo-1446582186851-3fe172f6acb9?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDR8fHNwaWRlcndlYnxlbnwwfHx8fDE3NTcxNDQxNDN8MA&ixlib=rb-4.1.0&q=80&w=1200)
Ich war vor längerem schon über Frank Westphals Artikel zur Website-Pflege gestolpert und hatte ihn interessiert verfolgt, aber nicht weiter darüber nachgedacht, geschweige denn adaptiert. Jedoch betreibe auch ich ein Weblog was es schon lange gibt, genauer seit 2005. Es hat ca. 4700 Artikel (der überwiegende Teil ist murks, so wie wenn man laufen lernt und später Langstrecke rennt, kann man nicht vergleichen) mit noch mehr Links. Und davon sind mit Sicherheit auch ganz viele ganz kaputt.
Frank Westphals Artikel wurde nun heuer von Felix aufgenommen, übernommen und er hat sich ans Werk gemacht. Er betreibt seine Website schon fast länger als viele andere Menschen auf der Welt sind, steckt sehr viel Energie, Liebe und Zuwendung hinein und beschäftigt sich täglich mit ihr. Natürlich hat auch er ein großes Interesse, für sich aber vor allem auch für seine Leser, eine bestmögliche Erfahrung zu bieten, wenn sie seine Seiten besuchen und durchstöbern.
Kaputte Links machen das Web nicht lebendig (im Gegensatz zu jenem Song von Keimzeit: "… Graffitis machen graue Wände lebendig") sondern zerstören ein Stück weit das Gesamtgefüge. Genau genommen müsste man sagen: das Web wie es zu dem und dem Tag damals war. Oder jetzt. Für uns als Schreiber ist immer jetzt. Für den Leser ist es aber damals. Oder auch jetzt. Es ist schwierig, diese verschiedenen Zeitformen in einem Web was sich verändert, aber zu einem Zeitpunkt X so und so aussah, zu archivieren und zu übertragen. Und da kommen wir der Sache näher, was tun wir? Wir könnten versuchen:
- Kaputte Links in unseren Artikeln aufspüren und sich merken
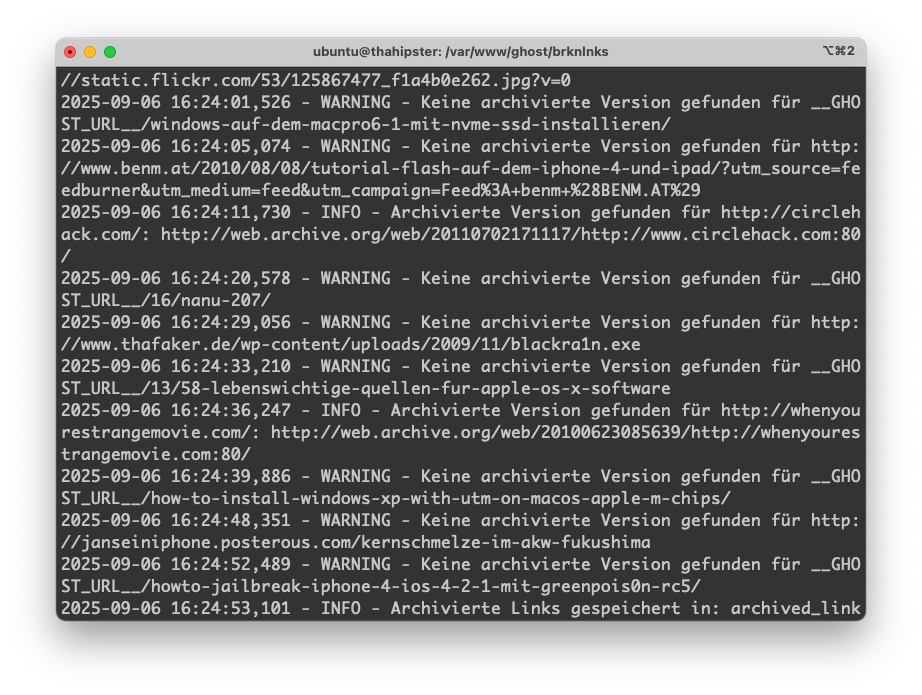
- auf Archive.org nachsehen ob es einen Snapshot vom Link gibt, der ungefähr auf die Zeit passt, aus der unser ursprünglicher Artikel stammt
- unsere kaputten Links mit denen aus Archive.org austauschen
Das ist dieser Dreiklang mit dem wir wahrscheinlich ziemlich viel reparieren können. Und das ist wahnsinnig spannend. Denn dann haben wir in einem Artikel von 2007 kaputte Links auf Quellen oder Verweise durch Archive.org Link-Snapshots aus der gleichen Zeit versehen.
Das geschriebene Wort bleibt dadurch in einer der damaligen Zeit entsprechenden Gültigkeit. Der Leser kann, wenn er möchte, also im Kontext dessen weiter gehen, wie er es damals getan hätte. Aber heute. Und Zusammenhänge bleiben weiter bestehen.
Warum Archive.org fürs Netz wichtig ist (toggle)
Archive.org bewahrt das Web in seinen verschiedenen Zuständen — nicht nur als Momentaufnahme, sondern als fortlaufende Sammlung von Seiten, Bildern und Dokumenten. Das ist mehr als bloß Nostalgie: es bedeutet, dass wir Entscheidungen, Debatten, Forschungsergebnisse und kulturelle Spuren auch Jahre später noch nachvollziehen können. Wenn Seiten verschwinden, Links sterben oder Inhalte verändert werden, bleibt mit der Wayback Machine ein öffentliches Gedächtnis erhalten.
Für Menschen heißt das konkret: Zugang zu verlorenen Informationen, Belege für historische Recherchen, Schutz vor Zensur und die Möglichkeit, digitale Kultur zu dokumentieren. Archive.org macht das Netz nicht statisch, sondern rekonstruierbar — und schenkt damit Journalist·innen, Forschenden, Aktivist·innen und allen neugierigen Nutzer·innen die Chance, die digitale Vergangenheit zu verstehen und daraus zu lernen.
Kurz: Archive.org konserviert das Internet, damit es nicht einfach verfällt — und macht damit einen unsichtbaren, aber unverzichtbaren Dienst für die Gesellschaft.
Natürlich haben wir mit meinem oben (durch Frank Westphal) skizzierten Dreiklang nur die Verweise auf Websites repariert. Da sind keine Dateien dabei, oder dynamische Webinhalte. Perl, PHP diesdas die sich über bestimmte URLs zur Laufzeit entwickelten. Oder nur manchmal. Aber wir haben einen Anfang geschaffen.
Aus diesem Grund sind veraltete Links um Längen besser als Löschen oder Abschalten. Tote Links sind belegende Artefakte, kein Mangel – richtig gekennzeichnet, zeigen sie Quellenlage. So lassen sich Inhalte oft noch rekonstruieren – über die URL, über Archive, über Kontext.
Die Library of Congress schreibt: „if anything, the value of a broken link seems to be increasing“.
Umsetzung
Tatsächlich haben mich die beiden Artikel inspiriert und dann habe ich die KI meiner Wahl gefragt, ob sie mir dabei helfen würde. Ich habe vorher entschieden den Dreiklang der Schritte auch in drei Scripte aufzuteilen und mir dabei helfen lassen in welcher Geschwindigkeit wir das durchführen sollten (langsam ist besser denn sonst könnten die gecrawlten Webserver sauer werden) und wie man das aufbereiten könnte. Auch habe ich keine große Erfahrung mit der Archive.org-API, die man aber gut mit ins Boot nehmen kann, um das vorhaben umzusetzen. Ich bin noch in der Umsetzung und habe gestern Abend damit angefangen.
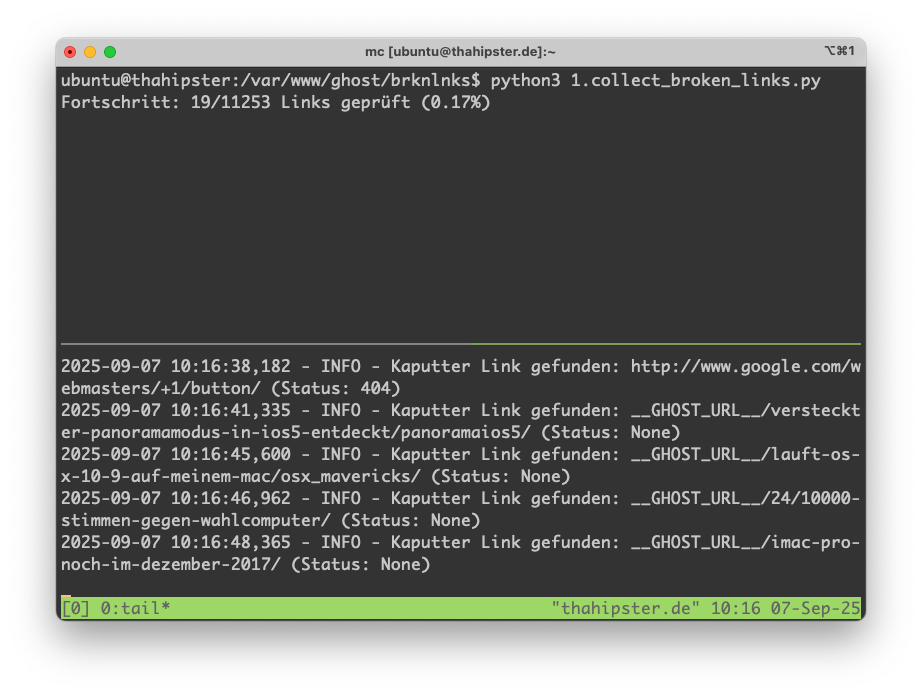
- Das Script zum Suchen von defekten Links (collect_broken_links.py) in meinen Artikel braucht von 21:34 gestern Abend bis heute morgen 4:56 Uhr.
- Das Script um archivierte Versionen der kaputten Links (find_archived_links.py) zu finden, Stage 2, läuft aktuell seit 08:53 Uhr (Update: bis 16:24 Uhr) und dann kommt ja noch der dritte Schritt,
- die gefundenen neuen Links von Archive.org für die kaputten in meinem Weblog auszutauschen. Das wird gefährlich und vorher muss ich alles backuppen, was ich so finde.
Ich benutze Ghost CMS für diese Website. Ich werde über die MySQL Datenbank direkt gehen. Die Tabelle mit ihren Feldern ist dokumentiert. Vielleicht ist es auch Postgres. Dann werde ich mit dem dritten Script also dafür Sorge tragen, im richtigen Feld der SQL Tabelle die entsprechend erkannten Links mit denen zu Archive.org zu ersetzen.
[UPDATE]
python3 repair_links.py
Stufe 3 abgeschlossen. 2364 Links ersetzt.
Conclusion
Das ganze lohnt sich weder bei janmontag.de noch bei herrmontag.de, denn diese Websites gibt es erst seit ca. 3 oder 5 Jahren. Hier sind auch wesentlich weniger Artikel vorhanden, sodass ich eine Pflege quasi per Hand betreiben kann, wenn mir etwas auffällt. Aber bei thahipster.de, da sieht das eben anders aus. Und da lohnt es sich. Auch weil viele meiner Artikel in Foren etc. verlinkt sind und tatsächlich Hilfe bieten. USB unter MS-DOS z.B., oder meine ganzen Apple Mac Artikel zum Tweaken diesdas. Wenn dann dort die Links immer funktionieren, ist das eine Hilfe für alle. Und für mich selbst.
Es ist unfassbar dass ich diese Webtechnologie von Anfang an mitbekommen habe, sie begleitet und genutzt habe, angefangen mit HTML Seiten Ende der 90er, mit Movable Type und Serendipity, mit b2evolution und Wordpress. Und am Ende mit verschiedenen SSG oder eben Ghost und Writefreely diesdas - aber ich bin von Anfang an dabei, nutze es seitdem und sehe jetzt, wie die Langzeitnutzung und Folgen Herausforderungen produzieren, mit denen ich mich gern beschäftige. Alt werden ist auch schön.
[UPDATE] Der Dreiklang hat erstaunlich gut funktioniert und einen vollen Tag gefordert. Ca. 8h lange tote Links suchen, dann ca 8h lang alle toten Links mit Äquivalenten von Archive.org ersetzen und am schnellsten ging dann das Update der Posts mit den neuen Links. Offensichtlich hat das alles vollautomatisch geklappt, wenn ich einen alten Artikel aufrufe, diesen hier, und dort einen Link versuche, dann führt er zu einem funktionierenden Archive.org Link aus der Zeit und ist mit dem Hinweis (archiviert) versehen worden.

Super cool.
Nachträge und Aktualisierungen
Ich habe das Script erweitert, denn mir ist aufgefallen, dass wir nach Prüfung der 11253 Links noch längst nicht alles erwischt haben, was problematisch ist. Aber so eine Reparatur, die ist ja auch ein Prozess.
- Links auf Domains die verkauft wurden und jetzt so eine Platzhalteseite haben. Die sind faktisch für das Script als erreichbar angesehen worden
- Seiten die den Artikel gelöscht und einfach einen Redirect auf ihre Startseite gesetzt haben. Wenn das nicht gekennzeichnet ist, merkt es das Script nicht.
Im Zuge dessen habe ich auch eine kleine Fortschrittsanzeige eingebaut und ein schöneres Logfile. Ich sehe also wie lange wir für die Links brauchen, ich lasse es jetzt noch mal komplett und vollständig laufen - es wird unendlich dauern. Weiterhin einbebaut habe ich, dass die Links weiter gekennzeichnet werden. Links zu Archive werden mit (archiviert) markiert, das steht dann einfach im Text hinter dem Link, und Links die wirklich tot sind, werden mit (Link nicht mehr verfügbar) markiert. Das finde ich transparent und nachvollziehbar. Möglich wäre auch, unterschiedliche Farben zu verwenden, aber das erschließt sich mir als Besucher nicht.
Hier ein Screenshot:
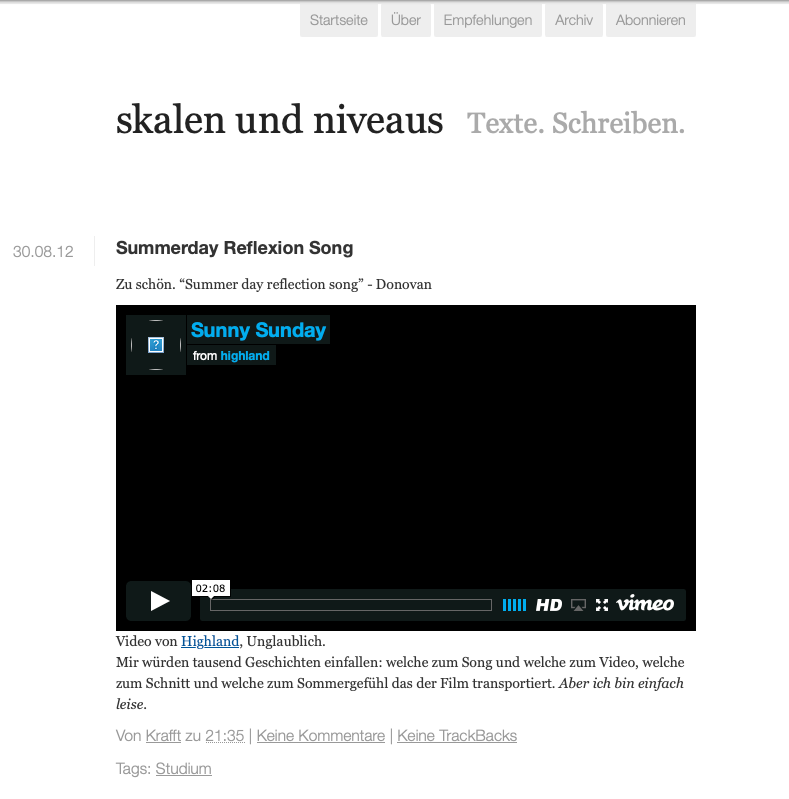
Oh, wie schön. Ca. 2012 herum habe ich das damals aktuelle Movable Type ausprobiert und ein Weblog "Skalen und Niveaus" betrieben, was ich sehr mochte. Leider habe ich weder die Artikel noch etwas anderes davon, aber gerade habe ich es in der Wayback Machine gefunden. Offensichtlich habe ich mir dafür das Alterego Krafft Prinzmetal (Über Krafft) zugelegt. :-) Und es gefällt mir immer noch 😄 Also das Weblog von damals, nicht unbedingt das Alterego :-) Was mir aber auch ausgesprochen gut gefällt, ist der Song den ich damals verlinkt habe.
Ich hab grad den schönen Summerday Reflection Song von Donovan auf meinem Weblog "Skalen und Niveaus" aus 2012 wieder gefunden. In der @waybackmachine.bsky.social, weil ich meine andere Website restauriere und hier ein Link her führte. Hach. Digitale Alzheimers. www.youtube.com/watch?v=-ctz...
— Herr_Montag_ 🌙 (@herrmontag.de) 7. September 2025 um 10:49
[image or embed]
Ein Screenshot: